Глава 9: Обучение и адаптация
Обучение и адаптация являются ключевыми факторами для улучшения возможностей агентов искусственного интеллекта. Эти процессы позволяют агентам развиваться за пределами предопределенных параметров, давая им возможность автономно улучшаться через опыт и взаимодействие с окружающей средой. Благодаря обучению и адаптации агенты могут эффективно справляться с новыми ситуациями и оптимизировать свою производительность без постоянного ручного вмешательства. В этой главе подробно рассматриваются принципы и механизмы, лежащие в основе обучения и адаптации агентов.
Общая картина
Агенты обучаются и адаптируются, изменяя свое мышление, действия или знания на основе нового опыта и данных. Это позволяет агентам эволюционировать от простого следования инструкциям к тому, чтобы становиться умнее со временем.
Обучение с подкреплением: Агенты пробуют действия и получают вознаграждения за положительные результаты и штрафы за отрицательные, изучая оптимальные поведения в изменяющихся ситуациях. Полезно для агентов, управляющих роботами или играющих в игры.
Обучение с учителем: Агенты учатся на размеченных примерах, связывая входные данные с желаемыми выходными результатами, что позволяет выполнять задачи принятия решений и распознавания паттернов. Идеально для агентов, сортирующих электронную почту или предсказывающих тренды.
Обучение без учителя: Агенты обнаруживают скрытые связи и паттерны в неразмеченных данных, помогая в получении инсайтов, организации и создании ментальной карты своей среды. Полезно для агентов, исследующих данные без конкретного руководства.
Обучение с несколькими/нулевыми примерами с агентами на основе LLM: Агенты, использующие LLM, могут быстро адаптироваться к новым задачам с минимальными примерами или четкими инструкциями, обеспечивая быстрые реакции на новые команды или ситуации.
Онлайн-обучение: Агенты непрерывно обновляют знания с новыми данными, что критично для реакций в реальном времени и постоянной адаптации в динамичных средах. Критически важно для агентов, обрабатывающих непрерывные потоки данных.
Обучение на основе памяти: Агенты вспоминают прошлый опыт для корректировки текущих действий в похожих ситуациях, улучшая контекстную осведомленность и принятие решений. Эффективно для агентов с возможностями вызова памяти.
Агенты адаптируются, изменяя стратегию, понимание или цели на основе обучения. Это жизненно важно для агентов в непредсказуемых, изменяющихся или новых средах.
Проксимальная оптимизация политики (PPO) — это алгоритм обучения с подкреплением, используемый для обучения агентов в средах с непрерывным диапазоном действий, таких как управление суставами робота или персонажем в игре. Его основная цель — надежно и стабильно улучшать стратегию принятия решений агента, известную как его политика.
Основная идея PPO заключается в том, чтобы делать небольшие, осторожные обновления политики агента. Он избегает резких изменений, которые могут привести к коллапсу производительности. Вот как это работает:
Сбор данных: Агент взаимодействует со своей средой (например, играет в игру), используя свою текущую политику, и собирает пакет опыта (состояние, действие, вознаграждение).
Оценка "суррогатной" цели: PPO рассчитывает, как потенциальное обновление политики изменит ожидаемое вознаграждение. Однако вместо простой максимизации этого вознаграждения он использует специальную "обрезанную" целевую функцию.
Механизм "обрезания": Это ключ к стабильности PPO. Он создает "область доверия" или безопасную зону вокруг текущей политики. Алгоритм предотвращается от внесения обновления, которое слишком отличается от текущей стратегии. Это обрезание действует как предохранительный тормоз, гарантируя, что агент не делает огромный, рискованный шаг, который отменяет его обучение.
Короче говоря, PPO балансирует улучшение производительности с сохранением близости к известной, работающей стратегии, что предотвращает катастрофические сбои во время обучения и приводит к более стабильному обучению.
Прямая оптимизация предпочтений (DPO) — это более новый метод, специально разработанный для согласования больших языковых моделей (LLM) с человеческими предпочтениями. Он предлагает более простую, более прямую альтернативу использованию PPO для этой задачи.
Для понимания DPO полезно сначала понять традиционный метод согласования на основе PPO:
- Подход PPO (двухэтапный процесс):
Обучение модели вознаграждения: Сначала вы собираете данные обратной связи от людей, где люди оценивают или сравнивают различные ответы LLM (например, "Ответ A лучше, чем Ответ B"). Эти данные используются для обучения отдельной AI модели, называемой моделью вознаграждения, задача которой — предсказать, какую оценку человек дал бы любому новому ответу.
Тонкая настройка с PPO: Затем LLM тонко настраивается с использованием PPO. Цель LLM — генерировать ответы, которые получают наивысший возможный балл от модели вознаграждения. Модель вознаграждения действует как "судья" в обучающей игре.
Этот двухэтапный процесс может быть сложным и нестабильным. Например, LLM может найти лазейку и научиться "взламывать" модель вознаграждения, чтобы получать высокие баллы за плохие ответы.
Подход DPO (прямой процесс): DPO полностью пропускает модель вознаграждения. Вместо перевода человеческих предпочтений в балл вознаграждения и затем оптимизации для этого балла, DPO использует данные предпочтений напрямую для обновления политики LLM.
Он работает, используя математическую связь, которая напрямую связывает данные предпочтений с оптимальной политикой. Он по сути учит модель: "Увеличь вероятность генерации ответов, подобных предпочтительному, и уменьши вероятность генерации подобных нежелательному."
По сути, DPO упрощает согласование, напрямую оптимизируя языковую модель на данных человеческих предпочтений. Это избегает сложности и потенциальной нестабильности обучения и использования отдельной модели вознаграждения, делая процесс согласования более эффективным и надежным.
Практические применения и случаи использования
Адаптивные агенты демонстрируют улучшенную производительность в изменчивых средах через итеративные обновления, управляемые данными опыта.
Агенты персонализированных помощников совершенствуют протоколы взаимодействия через лонгитюдинальный анализ поведения отдельных пользователей, обеспечивая высокооптимизированную генерацию ответов.
Агенты торговых ботов оптимизируют алгоритмы принятия решений, динамически корректируя параметры модели на основе высокоточных рыночных данных в реальном времени, тем самым максимизируя финансовую отдачу и снижая факторы риска.
Агенты приложений оптимизируют пользовательский интерфейс и функциональность через динамические модификации на основе наблюдаемого поведения пользователей, что приводит к увеличению пользовательского вовлечения и интуитивности системы.
Агенты робототехники и автономных транспортных средств улучшают навигационные возможности и возможности реагирования, интегрируя данные датчиков и анализ исторических действий, обеспечивая безопасную и эффективную работу в разнообразных условиях окружающей среды.
Агенты обнаружения мошенничества улучшают обнаружение аномалий, совершенствуя прогностические модели с новыми выявленными мошенническими паттернами, повышая безопасность системы и минимизируя финансовые потери.
Агенты рекомендаций улучшают точность выбора контента, используя алгоритмы изучения пользовательских предпочтений, предоставляя высоко индивидуализированные и контекстуально релевантные рекомендации.
Агенты игрового AI повышают вовлеченность игроков, динамически адаптируя стратегические алгоритмы, тем самым увеличивая сложность и вызов игры.
Агенты обучения базы знаний: Агенты могут использовать Retrieval Augmented Generation (RAG) для поддержания динамической базы знаний описаний проблем и проверенных решений (см. Главу 14). Сохраняя успешные стратегии и встреченные вызовы, агент может ссылаться на эти данные во время принятия решений, позволяя ему более эффективно адаптироваться к новым ситуациям, применяя ранее успешные паттерны или избегая известных ловушек.
Кейс-стади: Самосовершенствующийся агент программирования (SICA)
Самосовершенствующийся агент программирования (SICA), разработанный Максимом Робейнсом, Лоуренсом Айчисоном и Мартином Саммером, представляет собой достижение в области обучения на основе агентов, демонстрируя способность агента модифицировать свой собственный исходный код. Это контрастирует с традиционными подходами, где один агент может обучать другого; SICA действует как модификатор и модифицируемая сущность одновременно, итеративно совершенствуя свою кодовую базу для улучшения производительности в различных задачах программирования.
Самосовершенствование SICA работает через итеративный цикл (см. Рис. 1). Изначально SICA просматривает архив своих прошлых версий и их производительность в бенчмарк-тестах. Он выбирает версию с наивысшим баллом производительности, рассчитанным на основе взвешенной формулы, учитывающей успех, время и вычислительную стоимость. Эта выбранная версия затем предпринимает следующий раунд самомодификации. Она анализирует архив для выявления потенциальных улучшений, а затем напрямую изменяет свою кодовую базу. Модифицированный агент затем тестируется против бенчмарков, с записью результатов в архив. Этот процесс повторяется, способствуя обучению напрямую из прошлой производительности. Этот механизм самосовершенствования позволяет SICA развивать свои способности без требования традиционных парадигм обучения.

Рис. 1: Самосовершенствование SICA, обучение и адаптация на основе своих прошлых версий
SICA прошел значительное самосовершенствование, приведшее к достижениям в редактировании кода и навигации. Изначально SICA использовал базовый подход перезаписи файлов для изменений кода. Впоследствии он разработал "Умный редактор", способный к более интеллектуальным и контекстуальным правкам. Это эволюционировало в "Умный редактор с улучшением Diff", включающий диффы для целевых модификаций и редактирования на основе паттернов, и "Инструмент быстрой перезаписи" для снижения потребностей в обработке.
SICA далее реализовал "Оптимизацию минимального вывода Diff" и "Контекстно-чувствительную минимизацию Diff", используя парсинг абстрактного синтаксического дерева (AST) для эффективности. Дополнительно был добавлен "Нормализатор входных данных SmartEditor". В плане навигации SICA независимо создал "Локатор символов AST", использующий структурную карту кода (AST) для идентификации определений в кодовой базе. Позже был разработан "Гибридный локатор символов", сочетающий быстрый поиск с проверкой AST. Это было далее оптимизировано через "Оптимизированный парсинг AST в гибридном локаторе символов" для фокуса на релевантных секциях кода, улучшая скорость поиска (см. Рис. 2).
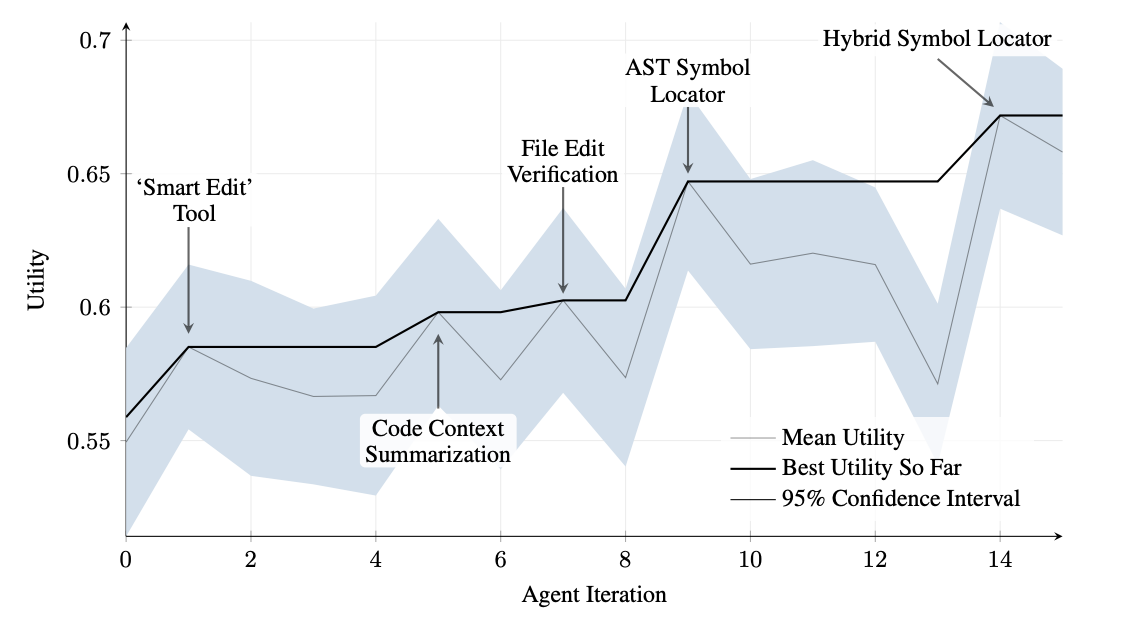
Рис. 2: Производительность по итерациям. Ключевые улучшения аннотированы с их соответствующими модификациями инструментов или агентов. (любезно предоставлено Максимом Робейнсом, Мартином Саммером, Лоуренсом Айчисоном)
Архитектура SICA включает базовый инструментарий для основных файловых операций, выполнения команд и арифметических вычислений. Она включает механизмы для отправки результатов и вызова специализированных под-агентов (программирования, решения проблем и рассуждения). Эти под-агенты декомпозируют сложные задачи и управляют длиной контекста LLM, особенно во время расширенных циклов улучшения.
Асинхронный наблюдатель, другая LLM, мониторит поведение SICA, выявляя потенциальные проблемы, такие как циклы или застой. Он общается с SICA и может вмешаться, чтобы остановить выполнение при необходимости. Наблюдатель получает детальный отчет о действиях SICA, включая граф вызовов и лог сообщений и действий инструментов, для выявления паттернов и неэффективностей.
LLM SICA организует информацию в своем контекстном окне, своей краткосрочной памяти, структурированным образом, критически важным для его работы. Эта структура включает системный промпт, определяющий цели агента, документацию инструментов и под-агентов, и системные инструкции. Основной промпт содержит постановку проблемы или инструкцию, содержимое открытых файлов и карту директорий. Сообщения ассистента записывают пошаговое рассуждение агента, записи вызовов инструментов и под-агентов и их результаты, и коммуникации наблюдателя. Эта организация облегчает эффективный поток информации, улучшая работу LLM и снижая время обработки и затраты. Изначально изменения файлов записывались как диффы, показывающие только модификации и периодически консолидирующиеся.
SICA: Взгляд на код: Более глубокое погружение в реализацию SICA раскрывает несколько ключевых дизайнерских решений, лежащих в основе его возможностей. Как обсуждалось, система построена с модульной архитектурой, включающей несколько под-агентов, таких как агент программирования, агент решения проблем и агент рассуждения. Эти под-агенты вызываются главным агентом, подобно вызовам инструментов, служа для декомпозиции сложных задач и эффективного управления длиной контекста, особенно во время тех расширенных итераций мета-улучшения.
Проект активно разрабатывается и стремится предоставить надежную платформу для тех, кто заинтересован в пост-обучении LLM на использование инструментов и других агентных задачах, с полным кодом, доступным для дальнейшего исследования и вклада в репозитории GitHub https://github.com/MaximeRobeyns/self_improving_coding_agent/.
Для безопасности проект сильно подчеркивает контейнеризацию Docker, означающую, что агент работает в выделенном Docker контейнере. Это критическая мера, поскольку она обеспечивает изоляцию от хост-машины, снижая риски, такие как непреднамеренная манипуляция файловой системы, учитывая способность агента выполнять команды shell.
Для обеспечения прозрачности и контроля система имеет надежную наблюдаемость через интерактивную веб-страницу, которая визуализирует события на шине событий и граф вызовов агента. Это предлагает всеобъемлющие инсайты в действия агента, позволяя пользователям инспектировать отдельные события, читать сообщения наблюдателя и сворачивать трассировки под-агентов для более ясного понимания.
В плане своего основного интеллекта, фреймворк агента поддерживает интеграцию LLM от различных провайдеров, позволяя экспериментировать с различными моделями для нахождения наилучшего соответствия для конкретных задач. Наконец, критическим компонентом является асинхронный наблюдатель, LLM, который работает параллельно с главным агентом. Этот наблюдатель периодически оценивает поведение агента на патологические отклонения или застой и может вмешаться, отправляя уведомления или даже отменяя выполнение агента при необходимости. Он получает детальное текстовое представление состояния системы, включая граф вызовов и поток событий LLM сообщений, вызовов инструментов и ответов, что позволяет ему обнаруживать неэффективные паттерны или повторяющуюся работу.
Заметным вызовом в начальной реализации SICA было побуждение агента на основе LLM независимо предлагать новые, инновационные, осуществимые и привлекательные модификации во время каждой итерации мета-улучшения. Это ограничение, особенно в стимулировании открытого обучения и подлинной креативности в агентах LLM, остается ключевой областью исследований в текущих исследованиях.
AlphaEvolve и OpenEvolve
AlphaEvolve — это агент AI, разработанный Google для обнаружения и оптимизации алгоритмов. Он использует комбинацию LLM, конкретно моделей Gemini (Flash и Pro), автоматизированных систем оценки и фреймворка эволюционных алгоритмов. Эта система стремится продвинуть как теоретическую математику, так и практические вычислительные приложения.
AlphaEvolve использует ансамбль моделей Gemini. Flash используется для генерации широкого спектра начальных предложений алгоритмов, в то время как Pro предоставляет более глубокий анализ и доработку. Предложенные алгоритмы затем автоматически оцениваются и оцениваются на основе предопределенных критериев. Эта оценка предоставляет обратную связь, которая используется для итеративного улучшения решений, приводя к оптимизированным и новым алгоритмам.
В практических вычислениях AlphaEvolve был развернут в инфраструктуре Google. Он продемонстрировал улучшения в планировании центров обработки данных, что привело к снижению использования глобальных вычислительных ресурсов на 0,7%. Он также внес вклад в дизайн аппаратного обеспечения, предлагая оптимизации для кода Verilog в предстоящих процессорных блоках Tensor (TPU). Кроме того, AlphaEvolve ускорил производительность AI, включая улучшение скорости на 23% в основном ядре архитектуры Gemini и до 32,5% оптимизации низкоуровневых инструкций GPU для FlashAttention.
В области фундаментальных исследований AlphaEvolve внес вклад в открытие новых алгоритмов для умножения матриц, включая метод для 4x4 комплексно-значных матриц, который использует 48 скалярных умножений, превосходя ранее известные решения. В более широких математических исследованиях он переоткрыл существующие современные решения для более чем 50 открытых проблем в 75% случаев и улучшил существующие решения в 20% случаев, с примерами, включающими достижения в проблеме поцелуев.
OpenEvolve — это эволюционный агент программирования, который использует LLM (см. Рис. 3) для итеративной оптимизации кода. Он оркестрирует пайплайн генерации кода, управляемой LLM, оценки и выбора для непрерывного улучшения программ для широкого спектра задач. Ключевым аспектом OpenEvolve является его способность эволюционировать целые файлы кода, а не ограничиваться отдельными функциями. Агент разработан для универсальности, предлагая поддержку множественных языков программирования и совместимость с OpenAI-совместимыми API для любой LLM. Кроме того, он включает многоцелевую оптимизацию, позволяет гибкую инженерию промптов и способен к распределенной оценке для эффективной обработки сложных задач программирования.

Рис. 3: Внутренняя архитектура OpenEvolve управляется контроллером. Этот контроллер оркестрирует несколько ключевых компонентов: семплер программ, базу данных программ, пул оценщиков и ансамбли LLM. Его основная функция — способствовать их процессам обучения и адаптации для улучшения качества кода.
Этот фрагмент кода использует библиотеку OpenEvolve для выполнения эволюционной оптимизации программы. Он инициализирует систему OpenEvolve с путями к начальной программе, файлу оценки и файлу конфигурации. Строка evolve.run(iterations=1000) запускает эволюционный процесс, выполняющийся 1000 итераций для нахождения улучшенной версии программы. Наконец, она выводит метрики лучшей программы, найденной во время эволюции, отформатированные до четырех десятичных знаков.
from openevolve import OpenEvolve
# Initialize the system
evolve = OpenEvolve(
initial_program_path="path/to/initial_program.py",
evaluation_file="path/to/evaluator.py",
config_path="path/to/config.yaml"
)
# Run the evolution
best_program = await evolve.run(iterations=1000)
print(f"Best program metrics:")
for name, value in best_program.metrics.items():
print(f" {name}: {value:.4f}")В двух словах
Что: Агенты AI часто работают в динамичных и непредсказуемых средах, где предварительно запрограммированная логика недостаточна. Их производительность может деградировать при столкновении с новыми ситуациями, не предусмотренными во время их первоначального дизайна. Без способности учиться на опыте агенты не могут оптимизировать свои стратегии или персонализировать свои взаимодействия со временем. Эта жесткость ограничивает их эффективность и предотвращает достижение истинной автономии в сложных, реальных сценариях.
Почему: Стандартизированное решение — интегрировать механизмы обучения и адаптации, трансформируя статичных агентов в динамичные, эволюционирующие системы. Это позволяет агенту автономно совершенствовать свои знания и поведение на основе новых данных и взаимодействий. Агентные системы могут использовать различные методы, от обучения с подкреплением до более продвинутых техник, таких как самомодификация, как видно в самосовершенствующемся агенте программирования (SICA). Продвинутые системы, такие как Google AlphaEvolve, используют LLM и эволюционные алгоритмы для открытия совершенно новых и более эффективных решений сложных проблем. Непрерывно обучаясь, агенты могут осваивать новые задачи, улучшать свою производительность и адаптироваться к изменяющимся условиям без требования постоянного ручного перепрограммирования.
Правило большого пальца: Используйте этот паттерн при построении агентов, которые должны работать в динамичных, неопределенных или эволюционирующих средах. Он необходим для приложений, требующих персонализации, непрерывного улучшения производительности и способности автономно обрабатывать новые ситуации.
Визуальное резюме

Рис. 4: Паттерн обучения и адаптации
Ключевые выводы
Обучение и адаптация касаются того, как агенты становятся лучше в том, что они делают, и обрабатывают новые ситуации, используя свой опыт.
"Адаптация" — это видимое изменение в поведении или знаниях агента, которое происходит от обучения.
SICA, самосовершенствующийся агент программирования, самосовершенствуется, модифицируя свой код на основе прошлой производительности. Это привело к инструментам, таким как умный редактор и локатор символов AST.
Наличие специализированных "под-агентов" и "наблюдателя" помогает этим самосовершенствующимся системам управлять большими задачами и оставаться на правильном пути.
Способ организации "контекстного окна" LLM (с системными промптами, основными промптами и сообщениями ассистента) крайне важен для того, насколько эффективно работают агенты.
Этот паттерн жизненно важен для агентов, которые должны работать в средах, которые всегда меняются, неопределенны или требуют персонального подхода.
Построение обучающихся агентов часто означает подключение их к инструментам машинного обучения и управление потоком данных.
Агентная система, оснащенная базовыми инструментами программирования, может автономно редактировать себя и тем самым улучшать свою производительность в бенчмарк-задачах.
AlphaEvolve — это агент AI от Google, который использует LLM и эволюционный фреймворк для автономного открытия и оптимизации алгоритмов, значительно улучшая как фундаментальные исследования, так и практические вычислительные приложения.
Заключение
В этой главе рассматриваются критически важные роли обучения и адаптации в искусственном интеллекте. Агенты AI улучшают свою производительность через непрерывное получение данных и опыта. Самосовершенствующийся агент программирования (SICA) иллюстрирует это, автономно улучшая свои способности через модификации кода.
Мы рассмотрели фундаментальные компоненты агентного AI, включая архитектуру, приложения, планирование, мульти-агентное сотрудничество, управление памятью, и обучение и адаптацию. Принципы обучения особенно важны для скоординированного улучшения в мульти-агентных системах. Для достижения этого данные настройки должны точно отражать полную траекторию взаимодействия, захватывая индивидуальные входы и выходы каждого участвующего агента.
Эти элементы способствуют значительным достижениям, таким как Google AlphaEvolve. Эта система AI независимо открывает и совершенствует алгоритмы с помощью LLM, автоматизированной оценки и эволюционного подхода, продвигая прогресс в научных исследованиях и вычислительных техниках. Такие паттерны могут быть объединены для построения сложных систем AI. Разработки, такие как AlphaEvolve, демонстрируют, что автономное алгоритмическое открытие и оптимизация агентами AI достижимы.
Литература
Sutton, R. S., & Barto, A. G. (2018). Reinforcement Learning: An Introduction. MIT Press.
Goodfellow, I., Bengio, Y., & Courville, A. (2016). Deep Learning. MIT Press.
Mitchell, T. M. (1997). Machine Learning. McGraw-Hill.
Proximal Policy Optimization Algorithms by John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. You can find it on arXiv: https://arxiv.org/abs/1707.06347
Robeyns, M., Aitchison, L., & Szummer, M. (2025). A Self-Improving Coding Agent. arXiv:2504.15228v2. https://arxiv.org/pdf/2504.15228 https://github.com/MaximeRobeyns/self_improving_coding_agent
Навигация
Назад: Глава 8. Управление памятью
Вперед: Глава 10. Протокол контекста модели